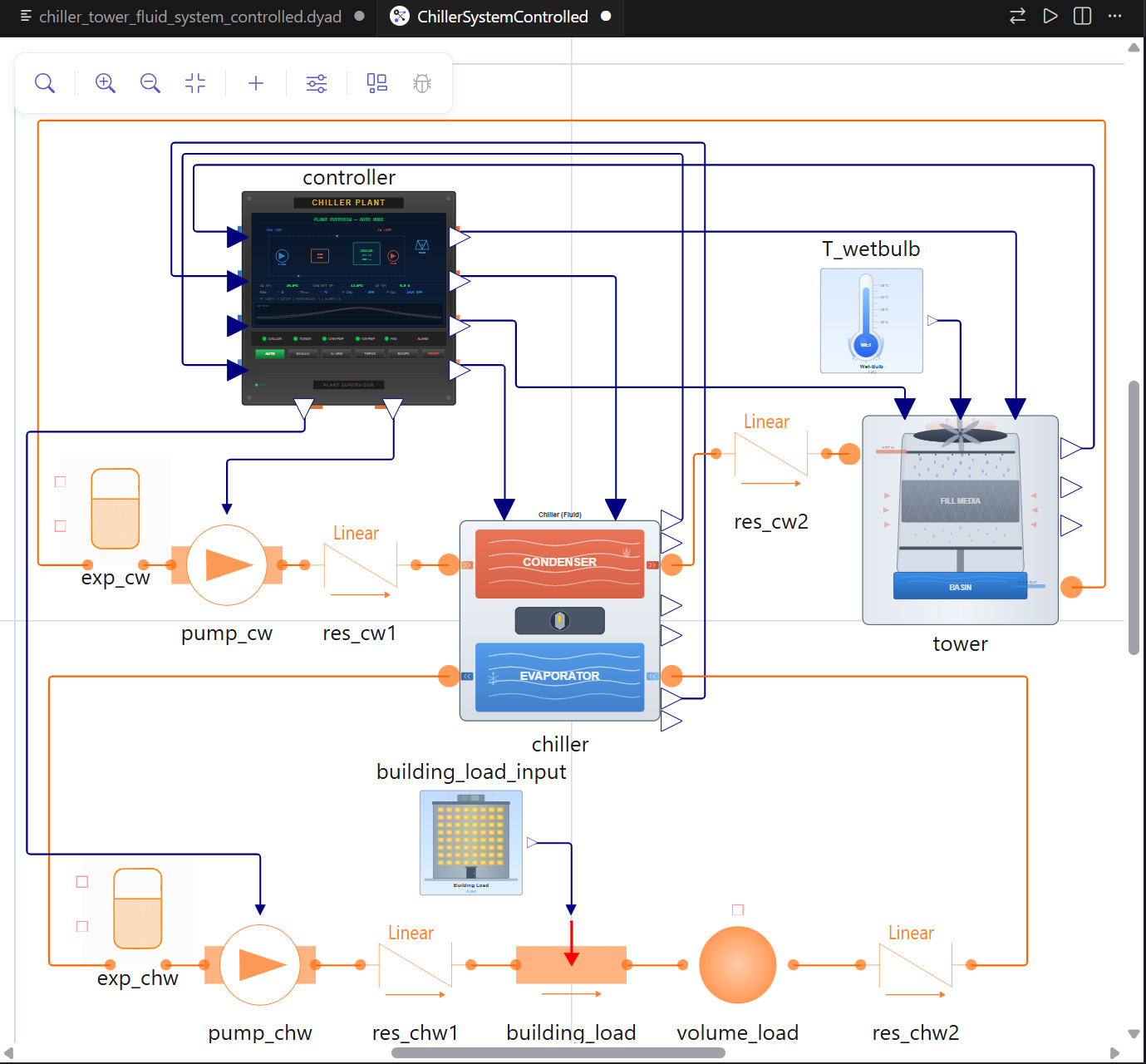
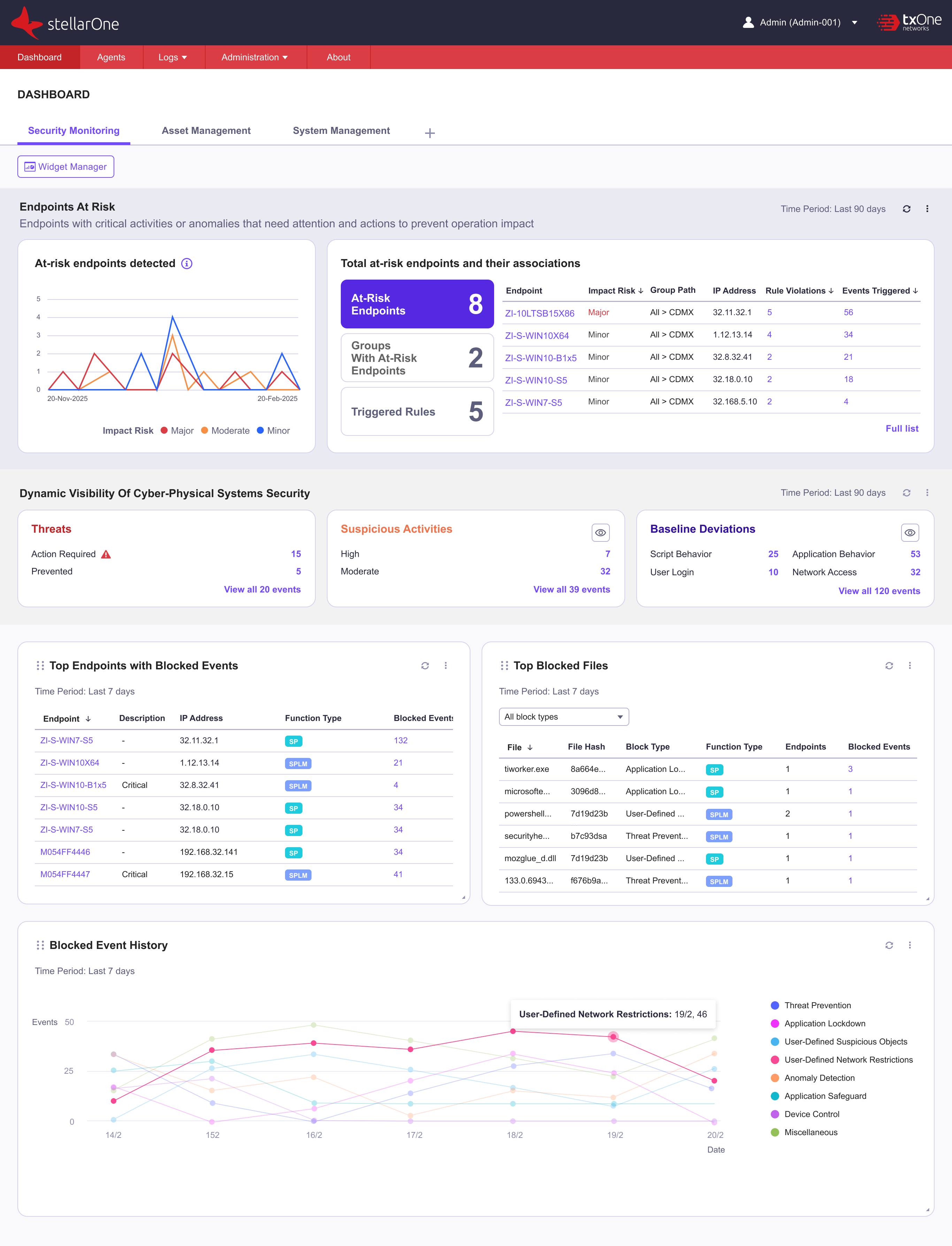
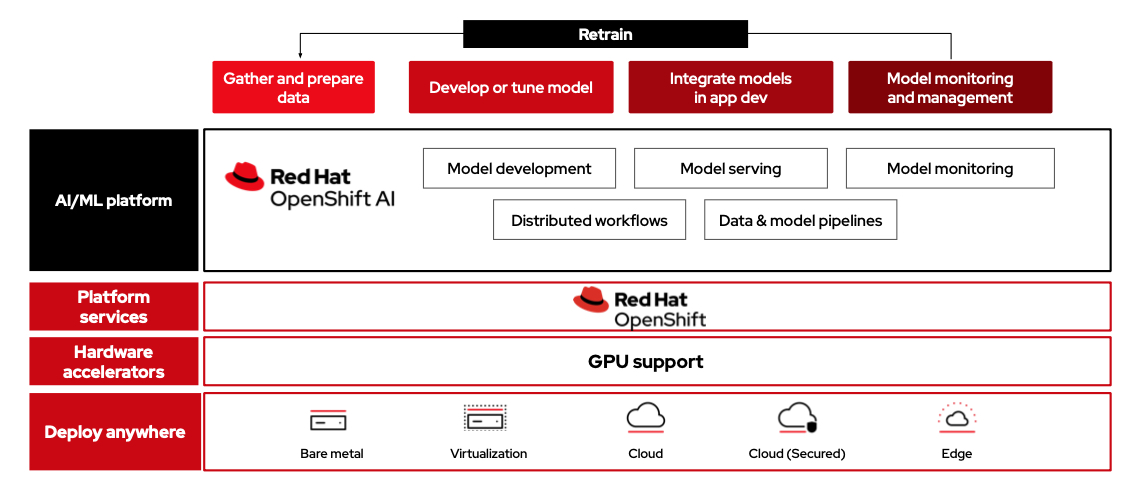
Mehrkernsysteme handhaben
Debugging- und Leistungsoptimierung
Grundlage für die optimale Nutzung von Mehrkernsystemen bildet eine sinnvoll partitionierte und auf mehreren Kernen ausgeführte fehlerfreie Software. Doch schwindender Zugang zu Schnittstellen und Bussen der Subsysteme und das gleichzeitige Verarbeitungsmuster erschweren das Debuggen solch komplexer Softwaresysteme. Daher benötigen Entwickler tiefgehende Kenntnisse über On-Chip-Debugging-Technologien, Tools und Techniken, mit deren Hilfe sich Debugging-Zyklen beschleunigen und Einschränkungen für derart komplexe Mehrkernsysteme überwinden lassen.
Bei der Entwicklung herkömmlicher Embedded Systeme mit Einzelkern liegt das Hauptaugenmerk auf der Debugging- und Leistungsoptimierung. Dabei geht es in erster Linie um das Debugging auf Kernebene und darum, Algorithmen zu verbessern. Doch Mehrkernsysteme gestatten keine optimale Skalierung mithilfe herkömmlicher Debugging- und Leistungsoptimierungstechniken. Zudem steigt die Komplexität aufgrund des System-on-Chip-Prinzips (SoC). So stellen die Transparenz der Analyse und die Optimierung interner Busübertragungen weiterhin eine Herausforderung dar. Ursprünglich konnten Programmierer spezielle Routinen zur Instrumentierung schreiben, um eine höhere Laufzeittransparenz zu erreichen. Diese Techniken sind jedoch mühsam sowie intrusiv und können das Anwendungsverhalten beeinflussen. Der Erfolg solcher herkömmlicher Ansätze ist zudem stark subjektiv zu betrachten. Verfügen Entwickler über kein detailliertes Verständnis auf Systemebene oder sind sie nicht mit der Codebasis vertraut, kann sich zudem die Entwicklungszeit verzögern.
System Trace-Technologie statt Core Tracing
Zur Beschleunigung der Debugging-Zyklen und zur Vermeidung des intrusiven Verhaltens war das Core Tracing bislang eine der am häufigsten verwendeten Technologien. Es bietet Ausführungstransparenz auf Kernebene ohne jegliche Code-Instrumentierung. Dieser Technologie fehlt jedoch eine systemweite bzw. SoC-weite Ansicht. Zur Realisierung der Transparenz auf Systemebene gewinnt daher die System Trace-Technologie (STM) zunehmend an Bedeutung. Sie bietet mit der Instrumentierung von Traces aus den Kernen unverzichtbare Funktionen, die mit Hardwareüberwachungsereignissen außerhalb des Prozessors kombiniert werden. Heutzutage bieten Halbleiterunternehmen wie Texas Instruments Bauteile mit STM-Funktionen, einschließlich hardwareunterstützter Softwareinstrumentierungsmechanismen und Hardwareereignissen, welche die Analyse von Busübertragungen, Leistungs- und Taktübergängen und der On-Chip-Leistungsüberwachung unterstützen. Eine der STM-Hauptfunktionen der On-Chip-Leistung bildet die Überwachung. Die Leistungsüberwachung ermöglicht eine nicht-intrusive Transparenz des komplexen SoC-Verbindungsnetzwerks, sodass sich die Eigenschaften der permanenten Datenbandbreite und Latenz besser nachvollziehen lassen, um letztendlich die Zielvorgaben bezüglich der Echtzeitleistung zu erreichen. Zugleich gibt die Überwachung Aufschluss über Metriken wie Durchsatz, Latenz, Vermittlungskonflikte und Auslastung für die Datenübertragung zu verschiedenen Datenflüssen. Diese Informationen sind für die Lösung von Problemen auf Ebene der Mehrkernsysteme sehr wichtig. Die Leistungsüberwachung wird als Teil der Open Core Protocol (OCP) L3-Verbindungsinfrastruktur implementiert und kann Links testen und Busereignisse aufzeichnen. Solche Ereignisse werden innerhalb eines benutzerdefinierten Abtastfensters berechnet, erfasst und regelmäßig über einen STM-Kanal gemeldet, wobei die Aufzeichnung mithilfe eines Trace-Empfängers erfolgt. Darüber hinaus bietet die Leistungsüberwachung Filter- und Auslösefunktionen, sodass der Schwerpunkt auf spezifische Initiatoren und Ziele gelegt werden kann.
Leistungsbewertung am Beispiel Videoanwendung
Eine typische SoC-Videoanwendung umfasst beispielsweise mehrere Verarbeitungsmodule, die mit dem externen freigegebenen Arbeitsspeicher (RAM) kommunizieren. Die Verarbeitungsmodule kann man sich als unabhängige Initiatoren vorstellen, das RAM kann als Target betrachtet werden. Zum besseren Verständnis von Engpässen ermöglicht die Leistungsüberwachung für die verarbeitenden RAM-Elemente die Bereitstellung einer Profilerstellung für den Datenverkehr. Die Abbildungen 1 und 2 zeigen Beispiele einer Leistungsüberwachung für ein Video, das mit einer Kamera mit STM-Leistungsüberwachungsfunktionen aufgenommen wurde. Beide Beispiele zeigen, wo die Leistungsbewertung erfolgt. Dazu werden Informationen zur durchschnittlichen Burstlänge und zum durchschnittlichen Durchsatz angegeben, die ein Bildverarbeitungssubsystem an der externen Speicherschnittstelle oder External Memory Interface (EMIF) erzeugt. In diesen Fällen untersucht die On-Chip-Leistungsüberwachung die Aktivität durch Verbinden von Messfühlern mit OCP-Signalen, mit deren Hilfe die EMIF-Last durch Berechnung der Datenverkehrsstatistik innerhalb eines Abtastfensters berechnet wird. Die Sonden erkennen OCP-Ereignisse für Last- und Wortübertragungen. Außerdem inkrementieren sie interne Zähler. Diese Zählerwerte werden berechnet, um bestimmte Informationen zu erhalten – beispielsweise die durchschnittliche Byte-Zahl pro Paket und den Durchsatz pro Abtastfenster – und regelmäßig über die STM-Schnittstelle an Anwender gemeldet. Grundsätzlich dauert eine solche Leistungsmessung im Gegensatz zur Anwendung der Softwareinstrumentierung oder anderer herkömmlicher Ansätze nicht mehrere Stunden oder Tage, sondern lediglich ein paar Minuten. Das in Abbildung 1 gezeigte Diagramm zeigt die durchschnittliche Anzahl von Bytes pro Paket (X-Achse) und Abtastperiode (Y-Achse). Aus den Messungen in dieser Abbildung geht hervor, dass sie innerhalb eines Video-Frames zwischen durchschnittlich 44 und 128Bytes pro Paket und Abtastfenster variiert. Die durchschnittliche Anzahl von Durchsatz-Bytes (X-Achse) pro Abtastperiode (Y-Achse), die dem EMIF-Durchsatztrend für die Videoaufnahme entspricht, ist in Abbildung 2 dargestellt. Die Messung in diesem Beispiel verdeutlicht, dass der durchschnittliche Durchsatz innerhalb eines Video-Frames zwischen 64 und 6.400Bytes pro Abtastperiode variiert.