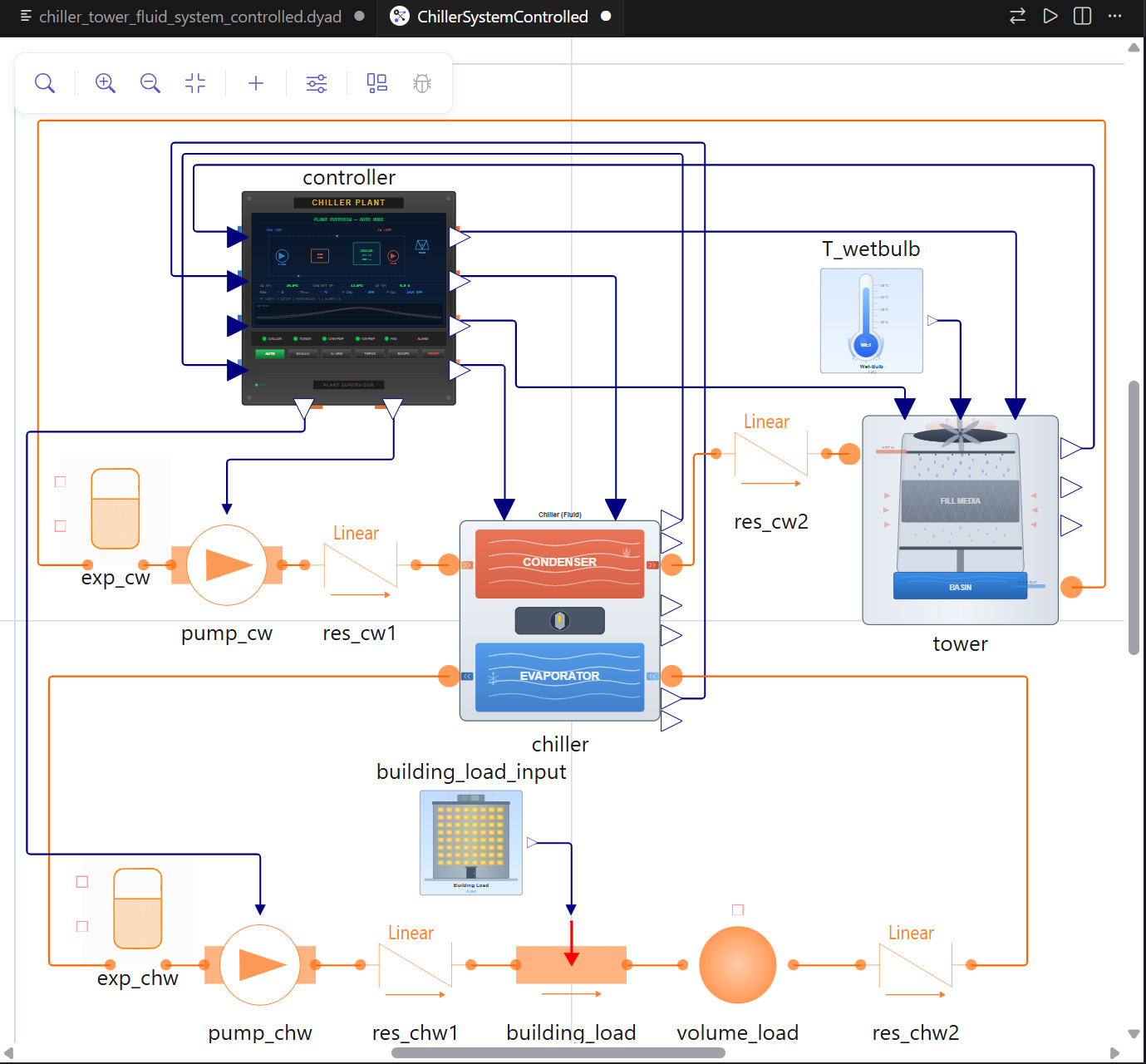
Embedded Grafikprozessoren als Rechenmaschinen GPGPU-Programmierung mit OpenCL
Heutige Embedded Grafikprozessoren sind massiv-parallele Rechenmaschinen, die frei programmierbar sind. In dieser Eigenschaft werden sie General Purpose Graphics Processing Units (GPGPUs) genannt. Programmieren kann man sie mit dem offenen und standardbasierten OpenCL Framework, mit dem man Rechenaufgaben auf CPUs, GPUs und DSPs verteilen kann, um so die Gesamtleistung eines Systems zu optimieren.
Neben dem guten „GFLOPS-pro-Dollar“-Verhältnis bieten GPGPUs eine hohe Performance pro Watt. Hochleistungsplattformen wie die AMD Radeon HD 6970 Grafikkarte liefern beispielsweise 10 GFLOPS pro Watt. Sie eignen sich jedoch aufgrund der Thermal Design Power (TDP) von 250 Watt vorrangig für serverbasierte Applikationen, bei denen man mit dieser Leistungsaufnahme problemlos umgehen kann. Bei vielen Embedded Applikationen muss der Grenzwert für die TDP deutlich geringer liegen. Gründe hierfür sind oft umgebungsbedingte Beschränkungen hinsichtlich Größe, Gewicht und Leistungsaufnahme (Size, Weight and Power = SWaP). Portable Ultraschallgeräte beispielsweise, sollen möglichst klein sein, benötigen aber eine hohe Rechenleistung für die Bildverarbeitung in Echtzeit. Auch Telekommunikations-Infrastrukturen, bei denen die Computing-Anforderung hoch, die Grenzen für die Leistungsaufnahme aber limitiert sind, können von GPGPU-Technologie profitieren. Viele Wehrtechnik- und Luftfahrt-Applikationen, wie beispielsweise Sonar, Radar und Videoüberwachung benötigen hohe Rechenleistung auf Embedded-Formfaktoren. Für diesen Bedarf liefert die AMD Radeon E6760 Embedded GPU mit 480 Stream-Prozessoren 16,5 GFLOPS pro Watt bei einer TDP von nur 35 Watt und damit eine Leistungsaufnahme, die für alle gängigen Embedded Systeme geeignet ist, die auf slotbasierten Rackmoutsystemen basieren wie beispielsweise PICMG 1.x, CompactPCI, VME, VPX, MicroTCA sowie AdvancedTCA.
Effiziente Algorithmen
Um von dem vollen Leistungspotential eingebetteter GPGPU-Anwendungen zu profitieren, ist zudem die Entwicklung grundlegender Algorithmen für spezifische GPU-Architekturen erforderlich. Zu den wichtigsten Algorithmen zählen lineare Gleichungen, Matrizenmultiplikationen, schnelle Fourier-Transformationen, Zufallszahlenerzeugung, elementare Funktionen wie z.B. Subtraktion, Summe, Teilung, Sortieren, etc. sowie domänenspezifische Algorithmen in der Bildverarbeitung . Eine weitere Aufgabe ist die Entwicklung paralleler Algorithmen. Einige Workloads sind beispielsweise nativ parallel. Entsprechende parallele Algorithmen liefern deshalb gegenüber Implementierungen auf Multi-Core CPUs eine viel höhere Leistung. Andere Algorithmen benötigen etwas mehr Aufwand, um sie auf eine massiv-parallele Umgebung zu portieren, aber die Ergebnisse können den Aufwand rechtfertigen. Untersuchungen haben ergeben, dass die Ausführung einer Single Precision General Matrix Multiply Routine (SGEMM) auf einer ATI Radeon HD5870 GPU bis zu 73 Prozent der theoretischen Single-Precision Floating-Point Leistung der GPU erreicht kann. Mit ihrer hohen Rechendichte und parallelen Natur ist SGEMM deshalb gut für die Implementierung auf GPGPU-Plattformen geeignet – insbesondere, wenn es um die Verarbeitung großer Matrizen geht.
Offener Standard
Das Potenzial zur parallelen Programmierung ist schon länger bekannt. Den Pionieren der GPGPU-Technologie standen jedoch noch keine Programmiersprachen zur Verfügung, um die massiv-parallele Rechenleistung der GPUs einfach abzurufen. Stattdessen griffen sie auf Grafikoperationen unter OpenGL zurück, welche vergleichbare mathematische Funktionen nutzten, wie sie zur Berechnungen einer bestimmten Aufgabe benötigt wurden. Anschließend kopierten sie die Ergebnisse dann aus dem Frame Buffer. Proprietäre GPGPU-Programmiersprachen wie CUDA und Brook+ vereinfachten zwar diese Nutzung, was jedoch nicht gelöst ist, ist die Portabilität der Algorithmen. Diese Situation führte zur Entwicklung von OpenCL (Open Computing Language) mit der Entwickler ihre Applikationen auf unterschiedliche Hardware (CPUs, GPUs und DSPs) verteilen können. OpenCL wurde 2008 von einem Industrie-Konsortium geschaffen. Heute sind viele Chip-Hersteller, Software-Firmen und Forschungseinrichtungen Mitglieder des Konsortiums, das sich um die Weiterentwicklung dieses offenen Standards für die parallele Programmierung in heterrogenen Umgebungen kümmert.