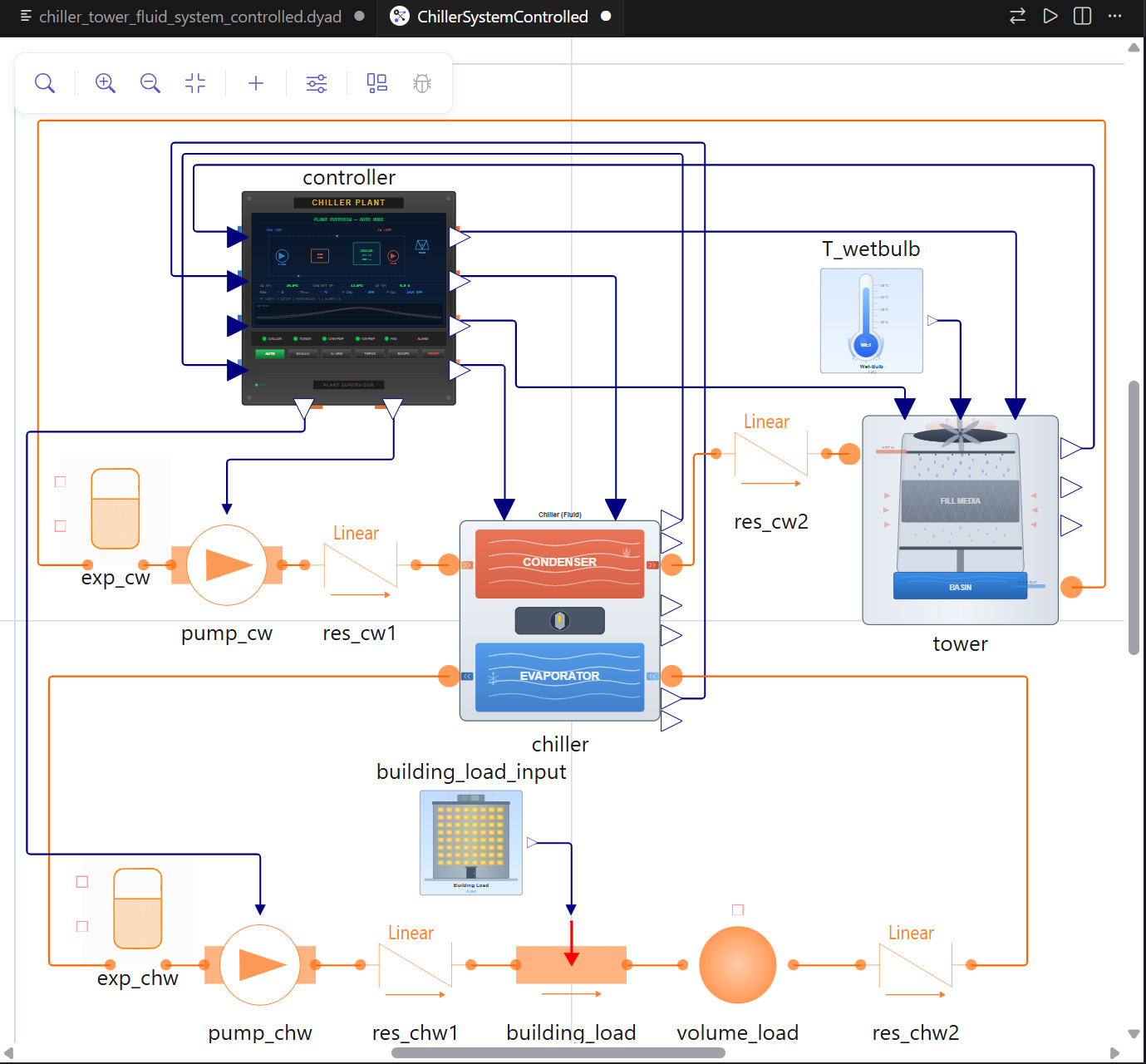
OpenCL
OpenCL ermöglicht vor allem eine Effizienzsteigerung bei der Entwicklung von heterogenen Computing-Anwendungen: Mit Hilfe von OpenCL können Applikationsentwickler effizient serielle Aufgaben auf die CPU und parallele Aufgaben auf die GPU verteilen. GPUs sind besonders gut für die parallele Datenverarbeitung geeignet, besonders wenn es um ähnliche Berechnungen großer Datenmengen geht (auch datenparallele Berechnungen genannt). Zur Illustration nutzen wir ein einfaches Beispiel: Eine einfache elementweise Addition von zwei Vektoren a und b, deren Ergebnis in den Vektor c geschrieben wird. Anstatt jeweils ein Paar von Elementen zu addieren, wie es der CPU Code handhabt, kann man OpenCL dazu verwenden, viele Additionen parallel auf der GPU durchzuführen. Das folgende Beispiel zeigt einen typischen Code-Schnipsel, um die Addition auf einer Single-Core CPU durchzuführen, sowie den Code eines sogenannten OpenCL-Kernels, welcher dieselbe Addition auf der GPU durchführt. Programmcode in C: void vec_add (const float *a, const float *b, float *c) { for (int i = 0; i++) c[i] = a[i] + b[i]; } Dieselbe Addition als OpenCL Kernel: __kernel void vec_add (__global const float *a, __global const float *b, __global float *c) { int i = get_global_id(0); c[i] = a[i] + b[i]; } Die Operation für jedes Element i wird Work-Item genannt. Konzeptionell werden alle Work-Items in einem Kernel parallel ausgeführt. Man kann nicht sagen, ob das Work-Item i = x vor, gleichzeitig oder nach dem Work-Item i = y ausgeführt wird. Wir wissen lediglich, dass auf GPUs hunderte und sogar tausende von Work-Items parallel in der Ausführung sein können. OpenCL bietet allerdings einen Weg, Sätze von Work-Items in Arbeitsgruppen zusammenzufassen. In der Regel können Work-Items sich nicht untereinander synchronisieren oder Daten austauschen, aber Work-Items innerhalb der gleichen Arbeitsgruppe können es. Das ermöglicht es, OpenCL-Kernel zu schreiben, die intelligenter sind, als wir in diesem Beispiel darstellen können. Neben dem Code, der auf der GPU ausgeführt wird, muss noch ein Host Programm geschrieben werden, um die GPU zu steuern und zu nutzen. Dieses Host Programm findet und initialisiert die GPU(s), sendet die Daten und den Kernel Code an die GPU, weist die GPU an, die Ausführung zu starten und liest die Ergebnisse aus der GPU aus.
Fazit
Da viele bestehende Algorithmen bereits hervorragend mit der GPGPU Architektur korrelieren und im Vergleich zu traditionellen Multi-Core CPU-Umsetzungen deutliche Leistungszuwächse zeigen, verspricht der Einsatz von OpenCL viele Vorteile bei der Applikationsauslegung. Performancesprünge alleine sind jedoch keine Rechtfertigung für entsprechende Entwicklungsaufwendungen. Auch der Preis muss passen. Da die GPGPU Technologie ansprechende GFLOPS-pro-Watt und -Dollar bietet und zudem neue Möglichkeiten für größen-, gewichts- und leistungssensitive Embedded Applikationen eröffnet, kann der Einsatz von GPGPU wesentlich zur Steigerung Performance und Systemeffizienz und somit letztlich zur Steigerung der Wettbewerbsfähigkeit beitragen. Mit OpenCL steht eine standard-basierte, parallele Entwicklungsumgebung zur Verfügung, mit deren Hilfe Entwickler diese Vorteile effizient in leistungsstarke Applikationen überführen können.